之前使用 angr 的断点功能在执行一个地址时打印出某个寄存器的值,因为默认开启了 vex ir 优化,把寄存器赋值操作给优化没了,所以开始我怎么也获取不到正确的寄存器值,被坑了一把,这里记录一下。
问题复现
0 mov eax, 0x1
5 mov eax, 0x2
a mov eax, 0x3
比如这三句汇编,如果我在地址 0x5 处下一个断点,断点停时获取到寄存器 eax 的值,很明显应该是 1 是吧,下面是 angr 的使用代码。
import angr
from angr import SimState
import logging
banned = ["angr.storage.memory_mixins.default_filler_mixin", "angr.engines.successors"]
for name in banned:
logging.getLogger(name).setLevel(logging.ERROR)
def debug_callback(state: SimState):
addr = state.inspect.instruction
print(f"Hook addr {hex(addr)}!")
print(f"eax value: {hex(state.solver.eval(state.regs.eax))}")
print(f"disass at {project.factory.block(addr).capstone.insns[0]}",)
print()
if __name__ == "__main__":
shellcode = bytes.fromhex(
"b801000000b802000000b803000000"
)
project = angr.load_shellcode(shellcode, "x86", 0)
opt_block = project.factory.block(0, opt_level=1)
print("asm:")
print(opt_block.pp())
state = project.factory.blank_state(addr=0)
state.inspect.b('instruction',instruction = 0x5, when=angr.BP_BEFORE, action=debug_callback)
sm = project.factory.simulation_manager(state)
while sm.active:
if sm.active[0].addr >= 0xf:
break
print("====> Current sm addr:", hex(sm.active[0].addr))
sm.step()
如果你尝试执行这段代码,会发现很不可思议的事情,获取到的 eax 值居然是 0!
asm:
_start:
0 mov eax, 0x1
5 mov eax, 0x2
a mov eax, 0x3
None
====> Current sm addr: 0x0
Hook addr 0x5!
eax value: 0x0
disass at 0x5: mov eax, 2
刚开始不太熟悉 angr 的我大为震撼,也没有什么解决的头绪,后面在一阵分析和扒拉源码后,我发现问题可能是出在 angr 执行的 vex ir 被优化了。
经过一番摸索后知道,如果通过 project.factory.block() 获取 block 再获取 vex ir,是可以设置 opt_level 来决定是否进行 vex ir 优化,默认是 opt_level = 1 进行优化。
opt_block = project.factory.block(0)
print("optimized vex ir:")
print(opt_block.vex)
unopt_block = project.factory.block(0, opt_level=0)
print("unoptimized vex ir:")
print(unopt_block.vex)
来看一下结果,可以看到未优化的 vex ir 是按着汇编语义来的,而优化后 vex ir 直接把整个 block 操作优化成给 eax 赋值 3 了,0x0 和 0x5 位置都优化掉了。因此会出现前面情况,即我们按默认的进行 vex ir 优化执行来设断点,在执行到 0x5 位置打印 eax 的值,发现居然是 0。
optimized vex ir:
IRSB {
t0:Ity_I32
00 | ------ IMark(0x0, 5, 0) ------
01 | ------ IMark(0x5, 5, 0) ------
02 | ------ IMark(0xa, 5, 0) ------
03 | PUT(eax) = 0x00000003
NEXT: PUT(eip) = 0x0000000f; Ijk_Boring
}
unoptimized vex ir:
IRSB {
t0:Ity_I32
00 | ------ IMark(0x0, 5, 0) ------
01 | PUT(eax) = 0x00000001
02 | PUT(eip) = 0x00000005
03 | ------ IMark(0x5, 5, 0) ------
04 | PUT(eax) = 0x00000002
05 | PUT(eip) = 0x0000000a
06 | ------ IMark(0xa, 5, 0) ------
07 | PUT(eax) = 0x00000003
08 | PUT(eip) = 0x0000000f
09 | t0 = GET:I32(eip)
NEXT: PUT(eip) = t0; Ijk_Boring
}
解决方案
这些只是静态分析输出 block 的 vex ir,是和执行无关的,那怎么设置 angr 执行时候不进行优化呢?经过我自己对源码的一番扒拉分析,发现如果在创建 state 时候传入参数 add_options={"NO_CROSS_INSN_OPT"},是可以不执行优化的,能够正常获取执行到 0x5地址时 eax 的值为 1。
state = project.factory.blank_state(addr=0,add_options={"NO_CROSS_INSN_OPT"})
回顾发现
过了一段时间我整理这个问题,又进行了一番搜索,发现 angr 仓库的一个 issue 里面有讨论这个问题,提供了两个不同的方案,是通过设置 sm.step() 的参数 opt_level=0 或 num_inst=1 来控制不优化。
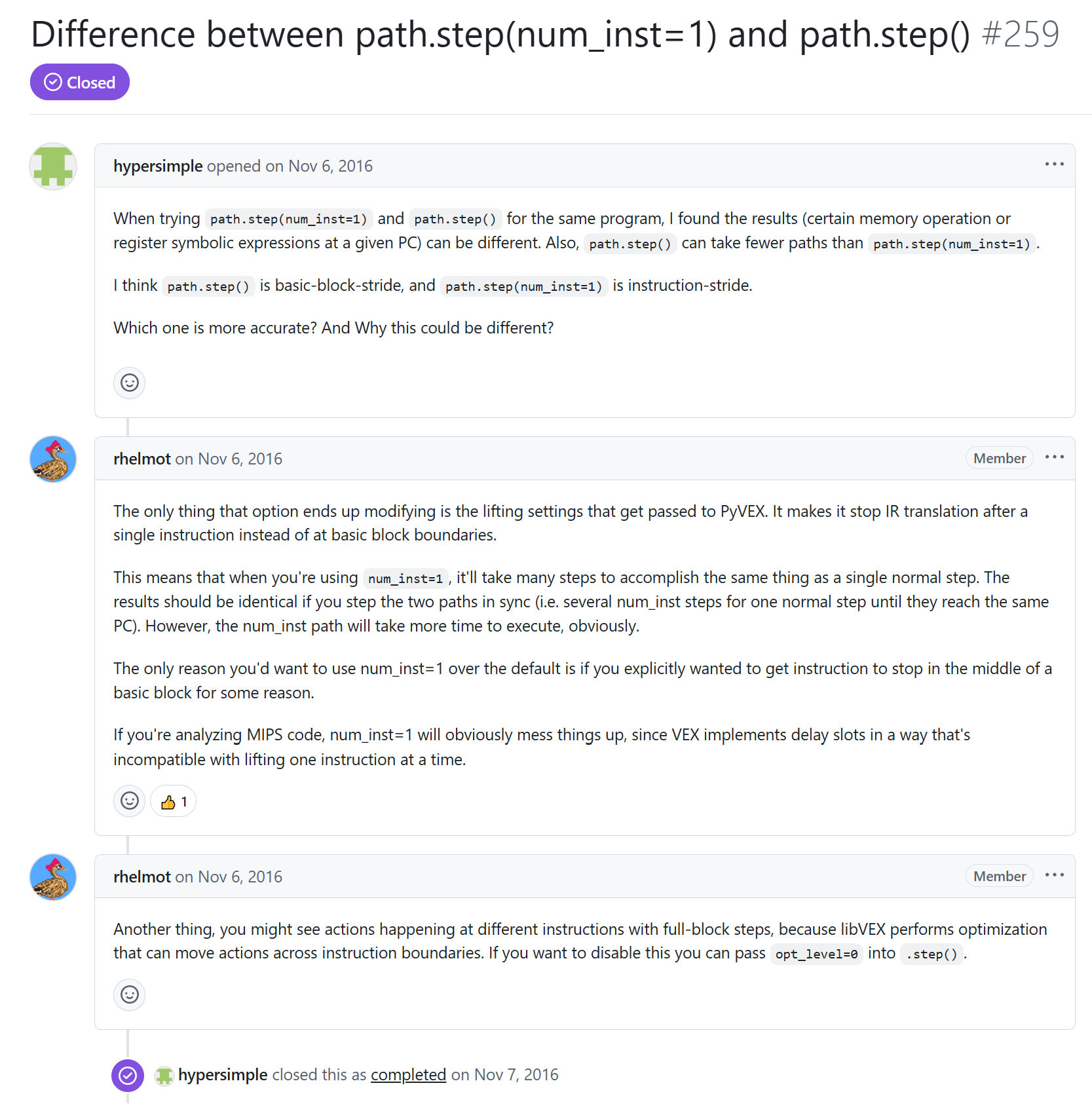
通过 angr 开发者 rhelmot 的回复可以知道,angr 的默认执行粒度是一个完整的基本块,step() 函数执行默认启用对 vex ir 进行优化,会致某些操作如内存访问的观察结果与预期不同,我碰到的就是寄存器优化问题。
若关注基本块级逻辑或追求效率,用默认的 step() 即可;如果优化干扰了分析,可通过 opt_level=0 禁用优化;若需精确分析指令级行为,可以使用 num_inst=1,但需注意 MIPS 延迟槽问题,在 MIPS 中,由于延迟槽指令与分支指令的耦合,num_inst=1 可能导致 IR 生成错误。